
2026 год, нужно ли писать SEO-статьи самостоятельно? Мои практические наблюдения и поворотный момент
Я помню, как в конце прошлого года руководитель отдела контента в нашей команде снова вызвал меня на «сердечный разговор». Тема была избитой: производство контента не успевает за потребностями SEO, база ключевых слов растет, а человеческих ресурсов ограниченно. Мы пробовали расширять штат, пробовали аутсорсинг, даже просили коллег-разработчиков выступить в роли писателей, но результат был либо взрывным ростом затрат, либо падением качества. Ощущение было такое, будто бежишь на беговой дорожке, а индикатор трафика SEO движется очень медленно.
В то время у меня была очень упрямая мысль: можно ли доверять тому, что пишет ИИ? Не говоря уже о том, чтобы конкурировать за позиции с независимыми сайтами и авторитетными СМИ, которые глубоко работают годами. Мы пробовали некоторые ранние инструменты генерации текста, но полученный контент либо был поверхностным, либо полон «правильных глупостей», читался как сборник из отраслевого словаря, лишенный реального понимания и убедительности. Кормить Google таким контентом было все равно что участвовать в конкурсе садоводов с пластиковыми цветами.
Смена парадигмы: от «накопления объема» к «стремлению к качеству»
Первоначальная трудность заключалась в объеме. У нас был длинный список ключевых слов, от основных продуктовых до длинных нишевых запросов, охватывающих десятки сегментов. По традиционному подходу, каждое слово требовало тщательно написанной статьи. Это привело к порочному кругу: чтобы обеспечить охват, мы были вынуждены снижать глубину и вложения в каждую отдельную единицу контента; а снижение качества контента, в свою очередь, влияло на позиции и кликабельность, многие статьи после публикации уходили в небытие, имея всего несколько посещений в месяц.
Я понял, что проблема, возможно, не в том, «сколько писать», а в том, «что писать» и «как писать». Мы начали анализировать страницы с высокими позициями. Очевидным общим моментом было то, что они редко представляли собой сухие описания функций или объяснения определений, а решали реальные проблемы в конкретных сценариях. Например, не «что такое граничные вычисления», а «почему граничные вычисления надежнее облачной передачи данных для контроля качества в реальном времени на производственных линиях?» — последнее содержит сценарий, сравнение и соображения для принятия решений.
Роль инструментов: от «писателя» к «сотруднику»
Смена парадигмы требовала поддержки инструментов. Если бы мы по-прежнему полагались на человеческие ресурсы для поиска сценариев, разработки углов зрения и организации материалов, узкое место в эффективности все равно осталось бы. В этот момент мы начали более систематически оценивать новые поколения платформ контента на базе ИИ. Нам нужен был не послушный «писатель», а «сотрудник», который понимает логику SEO, может быстро интегрировать информацию и организовывать контент в соответствии с поисковыми намерениями.
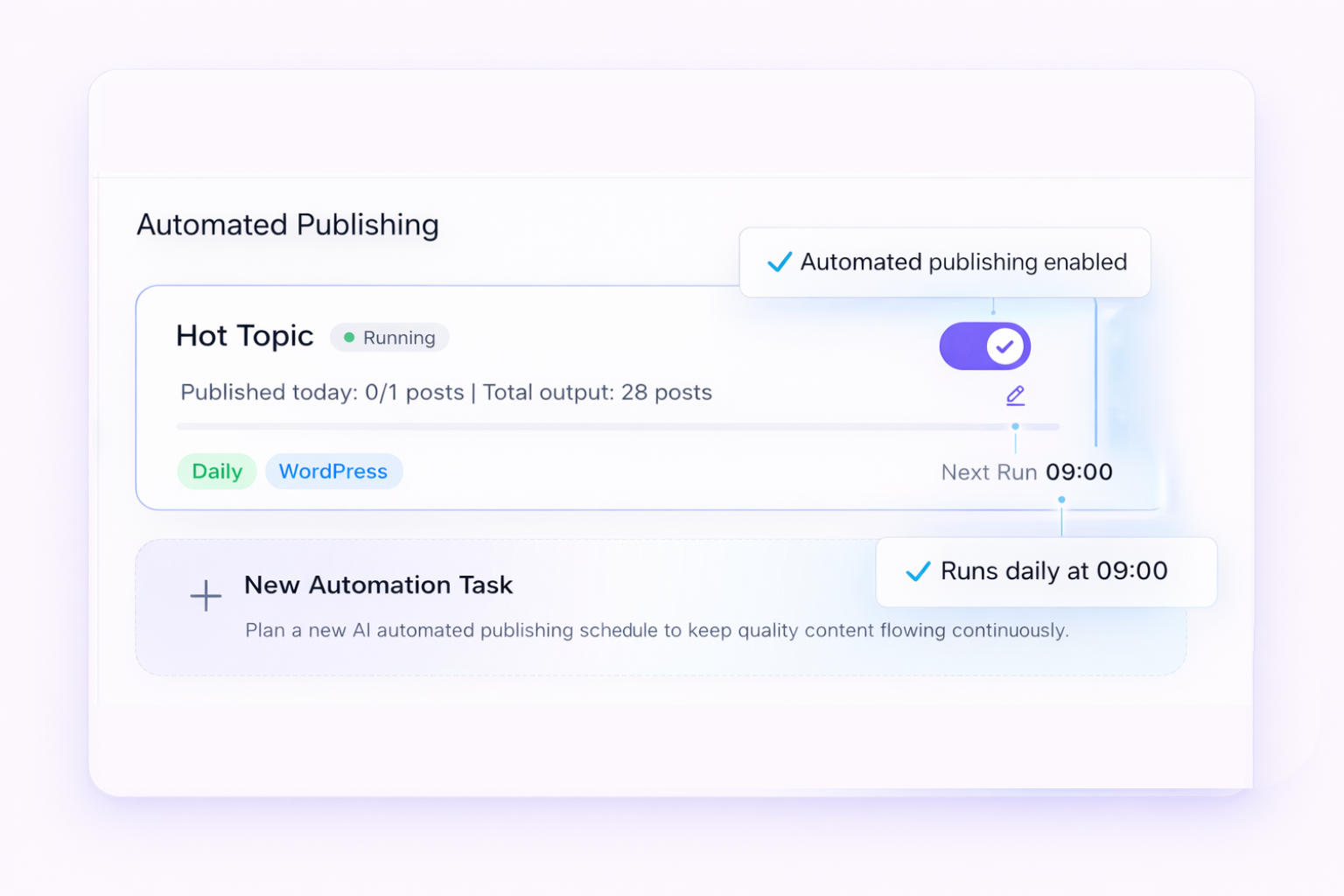
Мы внедрили SEONIB. Его подход показался мне довольно правильным: он не заставляет вас «создавать» тему с нуля, а позволяет генерировать структурированные черновики на основе четких ключевых слов или источников контента (например, ценного обсуждения в социальных сетях, отчета о тенденциях). Это важно, это гарантирует, что отправной точкой контента является реальный поисковый запрос или тема для обсуждения, а не воздушный замок.
Первый опыт использования оставил у меня глубокое впечатление. Я ввел длинный технический ключевой запрос, на который у нас никогда не было времени написать статью, выбрал шаблон «глубокий анализ» и установил относительно профессиональный тон. Скорость генерации была высокой. Я получил не полную, неоспоримую статью, а черновик с четкой структурой и аргументами, которые нужно было заполнить. Он содержал введение, ставил вопросы, перечислял несколько основных направлений аргументации, под каждым из которых были заполнители для данных и примеров, и, наконец, заключение. Более того, справа он предлагал рекомендации по оптимизации SEO, включая варианты переписывания заголовков и мета-описаний.
Это решило мою самую большую проблему: барьер для старта. Столкнувшись с пустым документом, я часто тратил много времени на построение структуры. А теперь этот самый трудоемкий этап был решен заранее. Моя работа заключалась в следующем: оценить, соответствует ли структура логике, заполнить ее отраслевыми примерами и данными, которые я знал, скорректировать акценты в аргументации, придать языку больше практического опыта нашей команды. SEONIB здесь играл роль скорее эффективного «первого автора» или «младшего научного сотрудника», он строил сцену, а я пел.
Неожиданные вызовы: однообразие контента и «привкус ИИ»
Вскоре мы перешли к этапу массового производства. Эффективность действительно повысилась, мы могли стабильно производить десятки единиц контента в неделю. Но возникли новые проблемы: контент начал проявлять признаки «шаблонизации». Хотя ключевые слова в каждой статье были разными, структура аргументации, обороты для переходов, даже шаблоны примеров были немного похожи. Я опасался, что не только читатели, но и алгоритмы поисковых систем могут заметить такой контент, лишенный уникальности.
Это заставило нас добавить новый этап в рабочий процесс: «внедрение человеческого понимания». Конкретно, для каждого черновика, сгенерированного ИИ, мы требовали от ответственного редактора или эксперта по продукту добавить как минимум одно-два конкретных наблюдения из нашей собственной практики, пройденные «грабли» или мнения, отличающиеся от общепринятых. Например, в статье о «мониторинге архитектуры микросервисов» мы больше не ограничивались перечислением таких инструментов, как Prometheus и Grafana, а добавили информацию о зоне слепой проверки неисправностей, возникшей у нас в сценарии с определенным клиентом из-за неправильной настройки частоты выборки логов, и последующем решении. Этот раздел контента был полностью оригинальным и «живым».
Другой проблемой была «свежесть». Контент, генерируемый ИИ на основе существующей информации, иногда не улавливал самые передовые технологические тенденции или рыночные изменения. Мы выработали привычку перед публикацией быстро проверять несколько отраслевых новостных источников или RSS-лент технических блогов, чтобы убедиться, что статья не содержит устаревших версий или опровергнутых мнений. В этом процессе помогли функции быстрого редактирования и перевода SEONIB, что позволило нам эффективно выполнять эти итерации.
Реальная обратная связь по трафику и конверсиям: какой контент действительно работает?
Публикация — это не конец. Мы создали простую панель мониторинга для отслеживания индексации каждой единицы контента, изменений позиций и органического трафика. За несколько месяцев данные выявили несколько контринтуитивных выводов:
- Не всегда длиннее лучше: Мы когда-то верили в глубокие статьи объемом более 2000 слов. Но данные показали, что некоторые «точные решающие» статьи, ориентированные на очень конкретные, практические вопросы (объемом около 800-1200 слов), хотя и не были длинными, имели стабильные позиции, а время пребывания пользователей и коэффициент конверсии (например, загрузки, консультации) были выше. Пользователям нужно быстрое решение проблемы, а не чтение учебника.
- «Намерение» ключевого слова важнее «популярности»: Мы когда-то безумно гнались за популярными словами с большим объемом поиска, но конкуренция была слишком высокой, и нам было трудно занять высокие позиции. Позже мы стали больше внимания уделять средне-низкочастотным длинным ключевым словам с четким поисковым намерением (особенно на «этапе принятия решений»). Например, по сравнению с «облачными вычислениями» и «расчетом затрат AWS Lambda против Azure Functions», трафик последнего может составлять лишь малую долю первого, но он приносит гораздо более сильное намерение потенциального клиента. Когда SEONIB генерирует контент на основе ключевых слов, чем точнее он может определить и сопоставить поисковое намерение (понять информацию, сравнить решения или решить проблему), тем лучше будет результат.
- Мультимедийные элементы — ключ к удержанию: Мы экспериментировали с вставкой в статьи диаграмм потоков, сравнительных диаграмм архитектуры и даже коротких GIF-демонстраций. С помощью встроенных функций SEONIB для генерации и интеллектуального встраивания изображений стоимость этого процесса снизилась. Данные ясно показали, что страницы, содержащие такие соответствующие изображения, имели заметно увеличенное среднее время сеанса.
Туманная зона будущего: оригинальность, авторитетность и границы ИИ
К настоящему моменту наша модель производства контента стабилизировалась как «черновик, сгенерированный ИИ + глубокое редактирование и внедрение понимания человеком». Это решило проблему производительности и в определенной степени обеспечило базовый уровень качества. Но у меня всегда оставались нерешенные вопросы, над которыми вся отрасль все еще размышляет в 2026 году:
- Где порог оригинальности? Когда все больше конкурентов используют схожие инструменты для генерации контента на основе схожих ключевых слов и общедоступных материалов, как сохранить уникальность контента? Сможет ли «человеческое понимание», на которое мы полагаемся, создать достаточно широкий ров?
- Как развиваются поисковые системы? Крупные поисковые системы, такие как Google, постоянно корректируют алгоритмы обнаружения и ранжирования контента, сгенерированного ИИ. Будут ли они все больше склоняться к поощрению контента, отражающего «опыт, профессионализм, авторитетность, достоверность» (E-E-A-T), особенно «опыт»? А это как раз то, в чем текущий ИИ слаб.
- Какова конечная ценность контента? Для получения трафика или для формирования узнаваемости бренда и доверия? Первое, возможно, можно достичь за счет масштаба и эффективности, второе же требует подлинно ценного, аргументированного, «человечного» общения. Достаточно ли в нашем процессе вложений в последнее?
У меня нет точных ответов. Возможно, будущее SEO-контента — это уже не «написание статей», а «построение динамической базы знаний, способной постоянно отвечать на вопросы пользователей». ИИ — это эффективный движок для построения этой базы знаний, но топливо и система навигации движка по-прежнему исходят из практики, размышлений и суждений людей в реальном мире.
FAQ
В: Будут ли поисковые системы наказывать за написание SEO-статей с помощью ИИ? О: По нашим практическим данным за последний год, пока контент в конечном итоге предоставляет пользователям ценную информацию и решает их проблемы, поисковые системы в настоящее время не имеют отдельной метки «сгенерировано ИИ» и не наказывают за это. Ключ в самом качестве контента, соответствует ли он поисковому намерению, обладает ли информативностью и читабельностью. Полностью неотредактированный, наполненный повторами и пустым содержанием текст ИИ, конечно, рискован. Но контент, прошедший ручную проверку и дополненный пониманием, показывает нормальные результаты в ранжировании.
В: Как избежать однообразия контента, сгенерированного ИИ? О: Наш основной метод — «дифференцированный ввод» и «постобработка». Не вводите только сухие ключевые слова, можно вводить ссылки на референсные статьи с мнениями и сценариями, цепочки обсуждений в социальных сетях, чтобы ИИ генерировал на основе более «граненых» материалов. Самое главное — после генерации должен быть этап ручной работы, добавление уникальных для вашей команды примеров, данных, неудачных уроков или необычных точек зрения. Это ключ к избавлению от «привкуса ИИ».
В: Какие статьи лучше всего подходят для генерации с помощью ИИ? О: По нашему опыту, эффективность наиболее заметно повышается в следующих типах: 1) Ответы на четкие ключевые слова (особенно длинные) и статьи-списки; 2) Популяризация базовых отраслевых знаний или объяснение терминов; 3) Черновики для быстрого отслеживания актуальных тенденций. А статьи «лидерства мнений», требующие глубокого отраслевого анализа, большого количества эксклюзивных данных или сильных личных мнений, где ИИ в настоящее время может помочь только в организации материалов.
В: Как обеспечить авторские права и оригинальность контента, сгенерированного ИИ? О: Это область, к которой нужно подходить осторожно. Ответственный подход заключается в следующем: при использовании инструментов выбирайте те, которые утверждают, что обучены на «чистых данных» и уделяют внимание оригинальности вывода. После генерации обязательно используйте инструменты проверки на плагиат. Более того, путем глубокого ручного редактирования, реорганизации и внедрения оригинального контента значительно измените окончательную форму текста, сделав его вашим «производным произведением». Перед публикацией мы убеждаемся, что оригинальность контента достигла установленного нами безопасного уровня.
В: Каков ваш текущий процесс производства контента? О: Упрощенно говоря: 1) Команда SEO или продуктовая команда предоставляет набор ключевых слов/тем с четким поисковым намерением. 2) Используя такие инструменты, как SEONIB, генерируются структурированные черновики на основе этих тем и предоставленных референсных материалов. 3) Редактор или эксперт в области берет на себя работу, проводит глубокое редактирование: проверяет факты, обновляет данные, удаляет избыточное, и самое главное — добавляет как минимум 1-2 эксклюзивных наблюдения или примера из собственной практики. 4) Оптимизируются заголовки, описания и мультимедийные элементы. 5) Публикация и переход в цикл мониторинга данных.